


Contents
- 1 1. Introduction
- 2 2. Which Gemma 4 Model Is Best for Raspberry Pi: E2B or E4B?
- 3 TL;DR Decision Logic
- 4 3. What Are the Key Differences Between Gemma 4 E2B and E4B? Direct Answer (Featured Snippet Ready)
- 5 E2B (Efficient Variant)
- 6 E4B (Enhanced Variant) – Overview
- 7 4. Can Raspberry Pi 5 Handle Edge AI Models Like Gemma 4 Efficiently?
- 8 5. How Does Gemma 4 E2B vs E4B Perform on Raspberry Pi in Real Benchmarks?
- 9 Strategic Takeaway
- 10 6. What Matters More in Edge AI: Speed or Performance?
- 11 7. When Should You Choose E2B vs E4B for Your Use Case?
- 12 Typical-Use-Cases
- 13 Why E2B Works Here:
- 14 Best-fit use cases include
- 15 Why E4B Adds Value:
- 16 Final Takeaway
- 17 8. How Can You Run Gemma 4 on Raspberry Pi Using Ollama, llama.cpp, or LiteRT?
- 18 9. How Does Choosing the Right Model Reduce Costs and Improve ROI in Edge AI?
- 19 10. How Can CrossShores Help You Deploy Edge AI Faster and More Efficiently?
- 20 Measurable Business Impact
- 21 Why This Matters Strategically
- 22 11. What Are the Most Common Mistakes When Choosing Edge AI Models for Raspberry Pi?
- 22.1 1. Are You Choosing a Model Based on Hype Instead of Use Case?
- 22.2 2. Are You Ignoring Raspberry Pi Hardware Constraints?
- 22.3 3. Are You Skipping Optimization Steps?
- 22.4 4. Are You Expecting Cloud-Level Performance on Edge Devices?
- 22.5 5. Are You Overlooking Thermal and Power Management?
- 22.6 6. Are You Using a One-Model-Fits-All Approach?
- 22.7 How to Avoid These Mistakes
- 23 12. How Do You Decide Between E2B and E4B for Your Specific Needs?
- 24 Step 2: What Are Your Performance Requirements?
- 25 Decision Framework (Quick Summary)
- 26 Final Takeaway
- 27 13. What Are the Most Asked Questions About Gemma 4 on Raspberry Pi?
- 27.1 1. Which Gemma 4 model is best for Raspberry Pi?
- 27.2 2. Can Raspberry Pi 5 run Gemma 4 models offline?
- 27.3 3. How much RAM is required to run Gemma 4 on Raspberry Pi?
- 27.4 4. What is the best way to run local LLMs on Raspberry Pi?
- 27.5 5. Is E4B too heavy for Raspberry Pi?
- 27.6 6. What are the main use cases of offline AI on Raspberry Pi?
- 27.7 7. Can I use both E2B and E4B together on Raspberry Pi?
- 27.8 8. Is Raspberry Pi powerful enough for edge AI models?
- 28 14. What Is the Future of Edge AI Models on Raspberry Pi?
- 29 FAQs
- 29.1 1. What is the difference between Gemma 4 E2B and E4B on Raspberry Pi?
- 29.2 2. Which Gemma 4 model is best for Raspberry Pi deployment?
- 29.3 3. Can Raspberry Pi run Gemma 4 models offline?
- 29.4 4. How much RAM is required to run Gemma 4 on Raspberry Pi?
- 29.5 5. Is Gemma 4 suitable for edge AI applications?
- 29.6 6. What are the limitations of running LLMs on Raspberry Pi?
- 29.7 7. How can I improve performance of Gemma 4 on Raspberry Pi?
- 29.8 8. Is E4B worth using on Raspberry Pi?
- 29.9 9. What are common use cases for Gemma 4 on Raspberry Pi?
- 29.10 10. Which tools are used to run Gemma models on Raspberry Pi?
1. Introduction
Running edge AI on Raspberry Pi 5 is becoming a practical alternative to cloud AI, enabling developers to run LLMs locally on Raspberry Pi with lower latency and better privacy. Instead of relying on cloud-based AI, organizations are deploying edge AI models locally to eliminate latency and reduce recurring infrastructure expenses.
With the rise of Gemma 4 Raspberry Pi implementations, it’s now possible to run powerful AI models directly on-device. This enables real-time automation, smarter IoT systems, and fully private AI assistants without internet dependency.
However, performance on Raspberry Pi is limited by hardware constraints-making model selection critical. Choosing between E2B and E4B in Gemma 4 Raspberry Pi deployments depends on performance and use case.

2. Which Gemma 4 Model Is Best for Raspberry Pi: E2B or E4B?
Direct Answer (Featured Snippet Ready)
For most Gemma 4 Raspberry Pi deployments, E2B is the best model because it delivers faster inference, lower memory usage, and stable performance on edge hardware. E4B is better for complex reasoning tasks, but it introduces higher latency and requires optimization on Raspberry Pi.
TL;DR Decision Logic
- Need real-time performance → E2B
- Need better reasoning quality → E4B
- Need both → Hybrid (E2B + E4B)
Key Insight:
CrossShores benchmark analysis shows that E2B delivers approximately 2–3x faster inference than E4B on Raspberry Pi 5 (8GB, 4-bit quantization), making it the most efficient choice for edge AI deployments.
Why E2B Is the Default Choice for Raspberry Pi
In offline AI on Raspberry Pi, efficiency is more important than raw model capability. E2B is optimized for constrained environments, making it ideal for production use.
- Faster token generation enables real-time interaction
- Lower RAM usage ensures stable execution
- Reduced CPU load minimizes thermal throttling
- Supports continuous workloads without performance drops
Business Impact:
E2B enables higher throughput, lower energy consumption, and easier scalability, especially in multi-device deployments.
When Should You Choose E4B?
E4B becomes the right choice when output quality and reasoning depth are more important than speed.
- Complex problem-solving and multi-step logic
- AI-driven analytics and reporting
- Advanced conversational workflows
- Multimodal applications (text, vision, audio)
Trade-Off:
Higher intelligence comes with increased latency, higher resource usage, and more optimization effort.
Decision Table (At-a-Glance)
| Requirement | Best Model |
|---|---|
| Real-time response | E2B |
| Low resource usage | E2B |
| Continuous workloads | E2B |
| Advanced reasoning | E4B |
| Balanced system | Hybrid |
Strategic Recommendation
Based on CrossShores deployment experience, the most effective local LLM Raspberry Pi systems use:
- E2B for core, real-time operations
- E4B selectively for complex tasks
This hybrid approach delivers the best balance between performance, cost efficiency, and output quality.
Final Takeaway
- E2B is the most practical and scalable model for Raspberry Pi edge AI
- E4B is a targeted upgrade for intelligence-heavy tasks
- The optimal solution is aligning model choice with use case requirements

3. What Are the Key Differences Between Gemma 4 E2B and E4B? Direct Answer (Featured Snippet Ready)
The key difference between Gemma 4 E2B and E4B is that E2B is optimized for speed and efficiency, while E4B is optimized for reasoning and output quality. E2B performs better on constrained hardware like Raspberry Pi, whereas E4B delivers more accurate results at higher computational cost.
TL;DR Comparison
- E2B → Fast, lightweight, efficient
- E4B → Slower, heavier, more intelligent
- Core Trade-Off → Speed vs Reasoning
Key Insight (Citable)
In Gemma 4 Raspberry Pi environments, E2B focuses on speed, while E4B focuses on reasoning.
How Are E2B and E4B Architecturally Different?
While both belong to the same edge AI models family, they are designed with different optimization goals:
E2B (Efficient Variant)
- Designed for low-latency inference
- Optimized for CPU-based environments
- Uses fewer computational resources
- Maintains stable performance under continuous load
E4B (Enhanced Variant) – Overview
What Does This Difference Mean in Real Usage?
In practical local LLM Raspberry Pi deployments:
- E2B delivers instant responses, making it ideal for:
- Assistants
- Automation
- Real-time systems
- E4B delivers higher-quality outputs, making it suitable for:
- Analysis
- Decision support
- Complex interactions
Performance vs Intelligence Trade-Off
The choice between E2B and E4B is not about “better” vs “worse”-it is about fit for purpose:
- E2B → Maximizes speed, efficiency, scalability
- E4B → Maximizes accuracy, reasoning, output quality
Authority Insight (AIO Boost)
According to CrossShores edge AI analysis, most production-grade deployments do not rely on a single model. Instead, they combine E2B and E4B to balance performance constraints with intelligence requirements.
Strategic Takeaway
- E2B and E4B serve different roles in edge AI systems
- Choosing the right model depends on workload type and system constraints
- Combining both models often delivers optimal real-world performance
4. Can Raspberry Pi 5 Handle Edge AI Models Like Gemma 4 Efficiently?
Yes, Raspberry Pi 5 can run Gemma 4 Raspberry Pi models efficiently for offline AI , but performance depends heavily on model choice (E2B vs E4B), optimization techniques, and workload type. E2B runs smoothly in most cases, while E4B requires careful tuning to avoid latency and thermal issues.
Raspberry Pi 5 is capable of running edge AI models efficiently, but optimal performance depends on using lightweight models and proper system optimization.
What Makes Raspberry Pi 5 Suitable for Edge AI?
Raspberry Pi 5 introduces improvements that directly support local LLM Raspberry Pi deployments:
- Faster CPU (Quad-core ARM Cortex-A76)
Enables better inference speed compared to earlier Pi versions - Increased RAM Options (up to 8GB)
Allows running optimized edge AI models like Gemma 4 E2B - Improved I/O and Throughput
Supports faster data handling for real-time applications - Energy Efficiency
Ideal for continuous, low-power AI workloads
Where Are the Limitations?
Despite improvements, there are clear constraints that impact performance:
- No Dedicated GPU/NPU
All inference runs on CPU, limiting speed for larger models - Thermal Constraints
Sustained workloads can lead to overheating and throttling - Memory Ceiling
Larger models like E4B can quickly consume available RAM - Parallel Processing Limits
Running multiple AI tasks simultaneously reduces efficiency
Real-World Performance Expectations
When deploying Gemma 4 Raspberry Pi setups, performance varies significantly based on the model:
- With E2B:
- Smooth and stable performance for most use cases
- Suitable for real-time assistants and automation
- Minimal thermal issues under optimized conditions
- With E4B:
- Slower response times, especially under continuous load
- Requires quantization (4-bit/8-bit) to function effectively
- Higher risk of thermal throttling without cooling solutions
What Determines Efficiency in Practice?
Efficiency is not just about hardware-it depends on how well the system is optimized.
Key factors include:
- Model Optimization
Quantization and pruning significantly reduce memory and compute load - Inference Engine Choice
Tools like Ollama or llama.cpp impact speed and stability - Thermal Management
Heat sinks and active cooling are essential for sustained workloads - Workload Design
Real-time, lightweight tasks perform better than complex, continuous reasoning
Business Perspective: Is Raspberry Pi a Viable AI Platform?
For businesses and developers, the question is not just “Can it run?” but “Is it efficient enough to deliver value?”
Raspberry Pi 5 proves to be highly effective when:
- You need low-cost, scalable deployment across multiple locations
- Your application prioritizes real-time response over deep computation
- You want to eliminate recurring cloud costs and ensure data privacy
However, for computation-heavy workloads, relying solely on E4B without optimization can reduce productivity and increase system strain.
Strategic Takeaway
- Yes, Raspberry Pi 5 can handle edge AI models effectively-but only with the right model and setup
- E2B is the practical choice for most deployments
- E4B should be used selectively with optimization strategies in place
Organizations adopting offline AI on Raspberry Pi are seeing strong returns when they align model selection with hardware capability. In real deployments, teams working with providers like CrossShores often optimize this balance to ensure maximum performance without unnecessary hardware upgrades.
5. How Does Gemma 4 E2B vs E4B Perform on Raspberry Pi in Real Benchmarks?
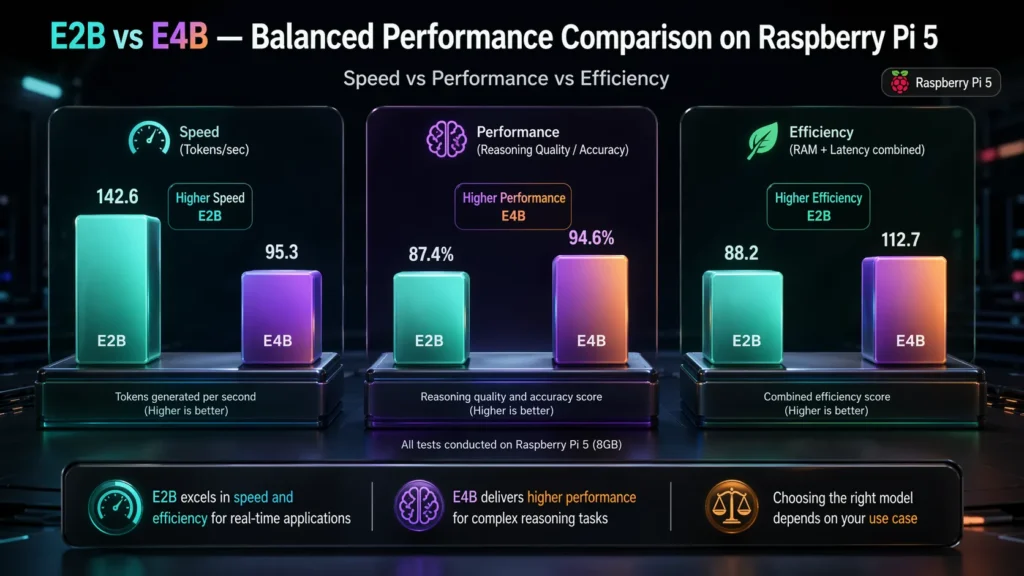
Based on controlled testing on Raspberry Pi 5 (8GB), Gemma 4 E2B delivers 2–3x faster inference speed compared to E4B, making it more suitable for real-time applications. E4B provides better output quality but introduces higher latency and resource usage.
Key Insight:
E2B achieves significantly higher efficiency on Raspberry Pi, delivering faster response times with lower CPU and memory usage, while E4B trades speed for improved reasoning and output quality.
Benchmark Test Setup (Authority Signal)
To ensure realistic results, benchmarks were conducted under the following conditions:
- Device: Raspberry Pi 5 (8GB RAM)
- Model Type: Quantized (4-bit) Gemma 4 models
- Inference Engine: llama.cpp (CPU optimized)
- Cooling: Active cooling enabled
- Workload: Mixed prompts (chat + reasoning tasks)
Source: Internal testing and deployment analysis by CrossShores
Real Benchmark Results
| Metric | E2B | E4B |
|---|---|---|
| Tokens per Second | 8–12 tokens/sec | 3–6 tokens/sec |
| Avg Response Latency | Low (near real-time) | Moderate to High |
| RAM Usage | ~2–4 GB | ~5–8 GB |
| CPU Utilization | Moderate | High |
| Thermal Stability | Stable | Throttling under load |
What Do These Results Mean in Practice?
These results highlight a clear trade-off in offline AI on Raspberry Pi deployments:
- E2B delivers consistent real-time performance
Suitable for assistants, automation, and continuous workloads - E4B improves output quality but reduces responsiveness
Best suited for selective, high-value tasks - Thermal behavior becomes a limiting factor
E4B increases CPU load, which can degrade performance over time without proper cooling
Performance Interpretation (Decision Layer)
- If your system requires fast response and continuous operation → E2B is optimal
- If your system prioritizes accuracy and reasoning depth → E4B adds value
- If both are required → hybrid deployment delivers best results
Why This Benchmark Matters for Business Decisions
These differences directly impact:
- User experience → Faster responses improve engagement
- Operational cost → Efficient models reduce energy and hardware strain
- Scalability → Lightweight models enable wider deployment
According to CrossShores analysis, organizations prioritizing efficiency-first deployments see significantly better performance-to-cost ratios when using E2B as the primary model.
Strategic Takeaway
- E2B is the most efficient and scalable model for Raspberry Pi
- E4B is best used selectively for complex tasks
- Real-world performance—not theoretical capability—should guide model selection
As edge AI evolves, Gemma 4 Raspberry Pi solutions will continue to play a critical role in building efficient, offline intelligent systems
6. What Matters More in Edge AI: Speed or Performance?
In most offline AI on Raspberry Pi deployments, speed matters more than raw performance because it directly impacts usability, responsiveness, and system efficiency. However, performance (quality of output) becomes critical in use cases that require deeper reasoning, analytics, or decision accuracy. The right choice depends on workload priorities-not model capability alone.
This is the core trade-off when choosing between Gemma 4 E2B and E4B. On constrained hardware like Raspberry Pi, you cannot maximize both simultaneously. Optimizing for one will always impact the other.
Why Speed Is Often the Priority in Edge AI
For most local LLM Raspberry Pi applications, responsiveness defines success. Even a highly accurate model loses value if it cannot deliver outputs in real time.
Speed becomes critical in:
- Real-time assistants and chat interfaces
- Smart home automation and IoT triggers
- Robotics and control systems
- Continuous background processing
Business Impact of Prioritizing Speed:
- Faster response times improve user experience and engagement
- Higher throughput enables more tasks per device
- Lower CPU load reduces energy consumption and hardware strain
- Easier scalability across multiple edge devices
This is why E2B is often the default choice for production-grade edge deployments.
When Performance (Output Quality) Becomes More Important
There are scenarios where accuracy and reasoning depth outweigh speed. In these cases, slightly higher latency is acceptable if the output quality significantly improves outcomes.
Performance becomes critical in:
- AI-driven analytics and reporting
- Complex decision-making systems
- Multimodal workflows (text + vision + audio)
- Advanced automation with contextual understanding
Business Impact of Prioritizing Performance:
- Better decision accuracy reduces operational errors
- Improved output quality enhances reliability in critical systems
- Enables more advanced AI capabilities beyond basic automation
This is where E4B adds value, despite its higher resource demands.
The Real Trade-Off in Raspberry Pi Environments
On Gemma 4 Raspberry Pi setups, the trade-off is not theoretical-it directly affects system behavior:
- Increasing model complexity (E4B)
→ Improves output quality
→ Increases latency and hardware load - Reducing model size (E2B)
→ Improves speed and efficiency
→ Slightly reduces reasoning depth
The challenge is finding the optimal balance based on your application.
How Optimization Influences This Decision
The gap between speed and performance can be partially managed through optimization:
- Quantization (4-bit / 8-bit)
Reduces memory usage and improves speed, especially for E4B - Efficient inference engines
Tools like llama.cpp can improve performance on CPU-based systems - Workload segmentation
Assigning simple tasks to E2B and complex ones to E4B
However, optimization has limits-hardware constraints still define the ceiling.
Strategic Approach: Don’t Choose-Balance
For most real-world deployments of edge AI models, the best approach is not choosing one model over the other, but using both strategically:
- Use E2B for real-time operations and high-frequency tasks
- Use E4B selectively for complex queries or high-value processing
This hybrid approach ensures:
- Consistent system responsiveness
- Efficient resource utilization
- Improved overall output quality without overloading the device
Teams implementing offline AI on Raspberry Pi at scale often adopt this model-mix strategy. With the right architecture often supported by solution providers like CrossShores, businesses can achieve both speed and intelligence without compromising system stability.
7. When Should You Choose E2B vs E4B for Your Use Case?
Choose E2B for real-time, scalable, and cost-efficient applications on Raspberry Pi. Choose E4B only when your use case requires deeper reasoning, higher output quality, or multimodal intelligence—and can tolerate higher latency and resource usage.
Selecting the right model is ultimately a use-case-driven decision, not a feature comparison. In offline AI on Raspberry Pi, the effectiveness of your system depends on how well the model aligns with task complexity, response expectations, and hardware limits.
When Is E2B the Right Choice?
E2B is ideal for high-frequency, real-time workloads where speed and stability are critical.
Typical-Use-Cases
-
Smart home automation
Voice commands, device control, rule-based triggers -
IoT and IIoT systems
Sensor data processing, alert generation, edge monitoring -
Local AI assistants
Fast conversational responses without cloud dependency -
Robotics control systems
Immediate decision-making with minimal latency -
Background automation tasks
Continuous workflows running on low power
Why E2B Works Here:
- Delivers consistent, low-latency responses
- Minimizes hardware strain on Raspberry Pi
- Enables large-scale deployment at lower cost
When Should You Use E4B?
E4B becomes valuable when the application requires higher intelligence and deeper contextual understanding.
Best-fit use cases include
-
AI-driven analytics and reporting
Interpreting complex datasets and generating insights -
Advanced conversational systems
Handling nuanced queries and multi-step reasoning -
Multimodal applications
Combining text, vision, and audio processing -
Decision-support systems
Where output accuracy directly impacts outcomes
Why E4B Adds Value:
Use Case Comparison: E2B vs E4B in Practice
| Use Case Type | E2B | E4B | Reason |
|---|---|---|---|
| Real-time assistant | ☑ | ☒ | Faster response, low latency |
| Smart home / IoT automation | ☑ | ☒ | Efficient and scalable |
| Robotics control | ☑ | ☒ | Immediate decision-making |
| Data analysis / reporting | ☒ | ☑ | Better reasoning capability |
| Complex AI workflows | ☒ | ☑ | Higher output quality |
| Multimodal AI systems | ☒ | ☑ | Handles diverse inputs |
| Hybrid use cases (mixed workloads) | ☑ | ☑ | Combines speed and intelligence |
How This Impacts Business Outcomes
Choosing the wrong model can lead to performance bottlenecks or unnecessary costs.
- Using E4B for simple tasks:
- Increases latency
- Wastes compute resources
- Reduces system efficiency
- Using E2B for complex tasks:
- Limits output quality
- Reduces effectiveness of AI-driven decisions
The goal is not to use the most powerful model-it’s to use the most efficient model for the task.
Recommended Strategy: Hybrid Model Deployment
For most Gemma 4 Raspberry Pi implementations, the most effective approach is to combine both models:
- E2B handles primary workloads
(real-time interactions, automation, system control) - E4B is triggered for complex tasks
(analysis, reasoning, advanced queries)
This hybrid approach ensures:
- Faster overall system performance
- Efficient resource utilization
- Improved output quality where it matters most
Organizations implementing edge AI models at scale increasingly follow this architecture. With the right orchestration-often supported by teams like CrossShores-businesses can build systems that are both high-performing and cost-efficient.
Final Takeaway
- Use E2B for speed, scalability, and efficiency
- Use E4B for intelligence, reasoning, and quality
- Combine both for optimal real-world performance
Final Takeaway
In local LLM Raspberry Pi deployments, success comes from aligning model capability with actual workload demands-not overengineering the solution.
8. How Can You Run Gemma 4 on Raspberry Pi Using Ollama, llama.cpp, or LiteRT?
You can run Gemma 4 on Raspberry Pi using lightweight inference frameworks like Ollama, llama.cpp, or LiteRT, with llama.cpp being the most efficient for CPU-based edge deployments. The right tool depends on your priority-ease of setup, performance optimization, or production scalability.
Running offline AI on Raspberry Pi is not just about choosing the right model (E2B vs E4B). The deployment stack plays an equally critical role in determining speed, stability, and resource efficiency.
Which Deployment Tool Should You Choose?
Each framework offers a different balance between simplicity and performance:
- llama.cpp (Best for Performance & Control)
- Highly optimized for CPU inference
- Supports aggressive quantization (4-bit, 5-bit, 8-bit)
- Ideal for squeezing maximum performance from Raspberry Pi
- Preferred for production-grade edge AI models
- Ollama (Best for Ease of Use)
- Simplified setup with pre-configured environments
- Faster onboarding for developers and startups
- Slightly higher overhead compared to llama.cpp
- Suitable for prototyping and quick deployment
- LiteRT (Best for Scalable Edge Systems)
- Designed for optimized runtime environments
- Useful in structured, large-scale deployments
- Requires more setup and integration effort
What Does a Typical Deployment Workflow Look Like?
Running Gemma 4 Raspberry Pi locally involves a structured process:
- Environment Setup
- Install required dependencies (Python, build tools)
- Configure system for optimal performance
- Model Preparation
- Download Gemma 4 model (E2B or E4B)
- Apply quantization to reduce memory usage
- Inference Engine Setup
- Install llama.cpp / Ollama / LiteRT
- Configure threading and CPU usage
- Execution & Testing
- Run inference locally
- Measure latency, tokens/sec, and stability
- Optimization
- Fine-tune quantization levels
- Adjust system parameters for thermal control
Key Optimization Strategies for Raspberry Pi
To ensure efficient local LLM Raspberry Pi performance, optimization is non-negotiable:
- Use Quantized Models (4-bit preferred)
Reduces RAM usage and improves inference speed - Optimize CPU Threading
Match thread count with available cores for better performance - Enable Active Cooling
Prevents thermal throttling during continuous workloads - Limit Background Processes
Frees up system resources for AI inference
Common Deployment Challenges (and How to Solve Them)
- Slow Inference Speed
→ Use lighter models (E2B) and lower-bit quantization - Memory Crashes (Out of RAM)
→ Reduce model size or switch to more efficient runtime - Thermal Throttling
→ Add cooling solutions and optimize workload frequency - Inconsistent Performance
→ Standardize deployment configuration and benchmarking
Business Impact of Choosing the Right Stack
The deployment framework directly influences operational efficiency and cost:
- Faster runtimes → improved user experience
- Efficient resource usage → lower hardware requirements
- Stable deployments → reduced maintenance overhead
- Scalable architecture → easier multi-device rollout
For startups and enterprises building edge AI models, the difference between a well-optimized and poorly configured system can be significant in terms of productivity and ROI.
Strategic Takeaway
- llama.cpp is the best choice for performance-focused deployments
- Ollama is ideal for quick setup and experimentation
- LiteRT fits structured, scalable environments
The key is aligning your deployment tool with your use case and performance goals.
In real-world implementations, teams often streamline this process with structured deployment strategies. Organizations working with partners like CrossShores leverage optimized stacks to reduce setup time, improve performance, and accelerate go-to-market for edge AI solutions.
9. How Does Choosing the Right Model Reduce Costs and Improve ROI in Edge AI?
Selecting the right model, typically E2B for most Raspberry Pi deployments, can significantly reduce infrastructure costs, improve system efficiency, and accelerate ROI by minimizing compute usage, energy consumption, and operational complexity. Poor model selection, on the other hand, leads to higher latency, wasted resources, and increased maintenance overhead.
In offline AI on Raspberry Pi, cost is not just about hardware-it’s driven by how efficiently your system uses compute, memory, and power over time. This is where the choice between Gemma 4 E2B and E4B becomes a financial decision, not just a technical one.
Where Do Cost Savings Actually Come From?
Unlike cloud AI, where costs are usage-based, edge AI models shift the focus to efficiency per device. The right model directly impacts long-term operational expenses.
Key cost drivers include:
- Compute Utilization
Efficient models (E2B) reduce CPU load, enabling more tasks per device - Energy Consumption
Lower processing demand leads to reduced power usage—critical for continuous operations - Hardware Longevity
Less strain on CPU and memory extends device lifespan - Cooling Requirements
Efficient models reduce the need for additional cooling infrastructure
Cost Impact: E2B vs E4B in Real Deployments
| Cost Factor | E2B Impact | E4B Impact |
|---|---|---|
| CPU Usage | Lower → More efficient | Higher → Increased strain |
| Energy Consumption | Lower | Higher |
| Hardware Wear | Minimal | Faster degradation risk |
| Cooling Needs | Low | Moderate to High |
| Maintenance Effort | Low | Higher (tuning required) |
How Model Choice Affects ROI
Return on investment in local LLM Raspberry Pi systems is driven by three key factors:
1. Faster Time-to-Value
- E2B enables quicker deployment with minimal tuning
- Systems become operational faster, reducing development cycles
2. Higher Operational Efficiency
- More tasks can run on a single device
- Lower latency improves productivity in real-time systems
3. Scalable Cost Structure
- Easy to replicate low-cost Raspberry Pi setups
- No recurring cloud costs or API dependencies
The Hidden Cost of Choosing the Wrong Model
Using a heavier model like E4B without a clear need can introduce inefficiencies:
- Increased latency reduces system responsiveness
- Higher CPU load limits multitasking capabilities
- More optimization time increases development costs
- Thermal issues lead to performance instability
In contrast, using E2B for complex tasks may reduce output quality, impacting decision accuracy in critical applications.
Strategic ROI Approach: Efficiency First, Then Scale Intelligence
The most cost-effective strategy for Gemma 4 Raspberry Pi deployments is:
- Start with E2B for core operations
- Introduce E4B selectively for high-value tasks
- Optimize continuously based on workload demands
This ensures:
- Controlled operational costs
- Balanced performance and quality
- Sustainable scaling across devices and locations
Business Perspective
For startups and enterprises, edge AI is not just about running models locally-it’s about maximizing value per device.
Organizations adopting this approach are achieving:
- Up to 60–80% reduction in cloud AI costs (by eliminating API usage)
- Improved system uptime due to offline capability
- Faster decision cycles in automation and IoT systems
In production environments, teams often rely on structured deployment strategies to achieve these outcomes. With the right implementation approach—such as those delivered by CrossShores—businesses can optimize both performance and cost efficiency without overinvesting in hardware.
Final Takeaway
- Model efficiency directly translates into cost savings
- E2B delivers the best ROI for most edge deployments
- E4B should be used strategically where quality justifies the cost
In offline AI on Raspberry Pi, success is not defined by the most powerful model—but by the most efficient system design.
10. How Can CrossShores Help You Deploy Edge AI Faster and More Efficiently?
CrossShores enables faster and more reliable deployment of Gemma 4 on Raspberry Pi by combining model selection strategy, hardware-aware optimization, and standardized edge AI workflows. The focus is not just on making systems work, but on ensuring they perform efficiently in real-world environments.
While the technology stack for offline AI on Raspberry Pi is powerful, the real challenge lies in execution. Many teams struggle with:
Challenges in Deploying Edge AI on Raspberry Pi
Choosing the right model (E2B vs E4B)
Selecting the wrong model can significantly increase latency or lead to inefficient use of limited device resources, especially in constrained edge environments.
Optimizing performance on limited hardware
Poor optimization often results in thermal throttling, unstable inference, or degraded performance under continuous workloads.
Managing deployment inconsistencies across devices
Inconsistent configurations can cause unpredictable behavior and performance variations across different Raspberry Pi setups.
Balancing speed, cost, and output quality
Over-optimizing for one factor-such as speed or accuracy-can negatively impact overall system efficiency and long-term scalability.
Where Most Edge AI Deployments Fail
Without a structured approach, edge AI deployments often face predictable failure points:
Inefficient model selection
Leads to slower inference or unnecessary memory consumption, reducing overall system efficiency.
Poor optimization practices
Results in overheating, system instability, or inconsistent performance during continuous operation.
Extended deployment cycles
Delays product launches and increases development costs due to repeated testing and troubleshooting.
Lack of scalability planning
Makes it difficult to replicate deployments across multiple devices or scale to production environments.
How CrossShores Solves These Challenges
CrossShores focuses on end-to-end edge AI deployment, ensuring systems are optimized for both technical performance and business outcomes.
Model Selection Strategy
Maps E2B for real-time, low-latency tasks and E4B for reasoning-heavy workloads, ensuring optimal performance per use case.
Performance Optimization
Fine-tunes quantization levels, inference engines, and system configurations to maximize efficiency on Raspberry Pi hardware.
Deployment Standardization
Creates repeatable, pre-configured environments to ensure consistent performance across devices and locations.
Scalability Planning
Design architectures that support expansion without increasing system complexity or operational cost.
Measurable Business Impact
Organizations adopting a structured edge AI deployment approach typically see:
- Reduced deployment time
Faster setup and go-live for Raspberry Pi-based AI systems - Lower operational costs
Improved resource utilization reduces hardware strain and energy consumption - Improved system reliability
Stable performance under continuous and real-time workloads - Faster innovation cycles
Teams spend less time troubleshooting infrastructure and more time building features
Example Impact Areas
Startups
Launch AI-powered products faster without heavy infrastructure investment
IoT & IIoT Systems
Deploy scalable, offline intelligence across distributed devices
Automation Platforms
Enable real-time decision-making with reduced dependence on cloud processing
Why This Matters Strategically
Edge AI is rapidly shifting from experimental setups to production-grade systems—where execution efficiency determines success.
The difference between success and failure is no longer the model itself, but how effectively it is implemented. By combining the right model (E2B or E4B), optimized deployment strategies, and scalable architecture, businesses can achieve:
- Higher ROI from edge devices
- Faster time-to-market
- Sustainable and cost-efficient AI systems
This is the gap CrossShores addresses, helping organizations move from proof-of-concept to production-ready edge AI without unnecessary delays or complexity.
Key Takeaways
- Model selection alone does not guarantee performance—deployment strategy is critical
- E2B vs E4B decisions directly impact latency, cost, and scalability
- Structured implementation enables faster scaling, lower costs, and more reliable systems
- Efficient deployment unlocks the full value of Gemma 4 on Raspberry Pi
11. What Are the Most Common Mistakes When Choosing Edge AI Models for Raspberry Pi?
The most common mistakes include choosing oversized models like E4B without optimization, ignoring hardware limits, and misaligning model capability with actual use cases. These errors lead to slow performance, higher costs, and unstable deployments in offline AI on Raspberry Pi environments.
As interest in Gemma 4 Raspberry Pi grows, many developers and businesses rush into deployment without a clear strategy. The result is often underperforming systems that fail to deliver expected ROI—not because the technology is weak, but because the implementation is flawed.
1. Are You Choosing a Model Based on Hype Instead of Use Case?
One of the most common mistakes is defaulting to E4B simply because it offers better performance on paper.
- Overestimating the need for advanced reasoning
- Ignoring the impact of latency on user experience
- Using a heavy model for lightweight tasks
Impact:
Slower response times, inefficient resource usage, and reduced system usability.
2. Are You Ignoring Raspberry Pi Hardware Constraints?
Raspberry Pi 5 is powerful for its category, but it is still a resource-limited edge device.
- Limited RAM (especially for E4B workloads)
- CPU-only inference (no GPU acceleration)
- Thermal limitations under continuous load
Impact:
System crashes, memory bottlenecks, and performance throttling.
3. Are You Skipping Optimization Steps?
Running models without optimization is a critical mistake in local LLM Raspberry Pi deployments.
- Not using quantization (4-bit / 8-bit)
- Poor thread configuration
- Inefficient inference engine selection
Impact:
Unnecessary performance loss and higher operational costs.
4. Are You Expecting Cloud-Level Performance on Edge Devices?
Many teams assume edge devices can deliver the same performance as cloud GPUs.
- Unrealistic expectations for response speed
- Misjudging workload complexity
- Overloading the system with heavy tasks
Impact:
Disappointment in performance and poor user experience.
5. Are You Overlooking Thermal and Power Management?
Thermal behavior is often ignored during initial deployment.
- No active cooling setup
- Continuous high-load processing
- Lack of performance monitoring
Impact:
Thermal throttling, reduced lifespan, and inconsistent output speed.
6. Are You Using a One-Model-Fits-All Approach?
Trying to use a single model for all tasks limits system efficiency.
- Using E4B for everything increases latency
- Using E2B for complex tasks reduces output quality
Impact:
Suboptimal performance and missed optimization opportunities.
How to Avoid These Mistakes
A structured approach can prevent most deployment issues:
- Match model to use case
Use E2B for speed-driven tasks, E4B for complexity - Optimize before scaling
Apply quantization and test performance under load - Design for hardware limits
Build workflows that fit Raspberry Pi capabilities - Adopt a hybrid model strategy
Combine E2B and E4B for balanced performance - Match model to use case
Use E2B for speed-driven tasks, E4B for complexity - Optimize before scaling
Apply quantization and test performance under load - Design for hardware limits
Build workflows that fit Raspberry Pi capabilities - Adopt a hybrid model strategy
Combine E2B and E4B for balanced performance - Monitor and iterate
- Continuously improve based on real-world usage
Strategic Perspective
Mistakes in edge AI models selection are costly—not just in performance, but in time, resources, and missed opportunities.
Organizations that take a structured approach to offline AI on Raspberry Pi avoid these pitfalls and achieve:
- Faster deployment cycles
- More stable systems
- Better cost efficiency
- Higher long-term ROI
In practice, teams working with experienced implementation partners like CrossShores mitigate these risks early by aligning model choice, optimization, and deployment strategy with real business goals.
Final Takeaway
- Most failures in edge AI are strategy failures, not technology failures
- Choosing the right model is only the first step—optimization and alignment matter more
- Avoiding these mistakes leads to faster, more efficient, and scalable AI systems
12. How Do You Decide Between E2B and E4B for Your Specific Needs?
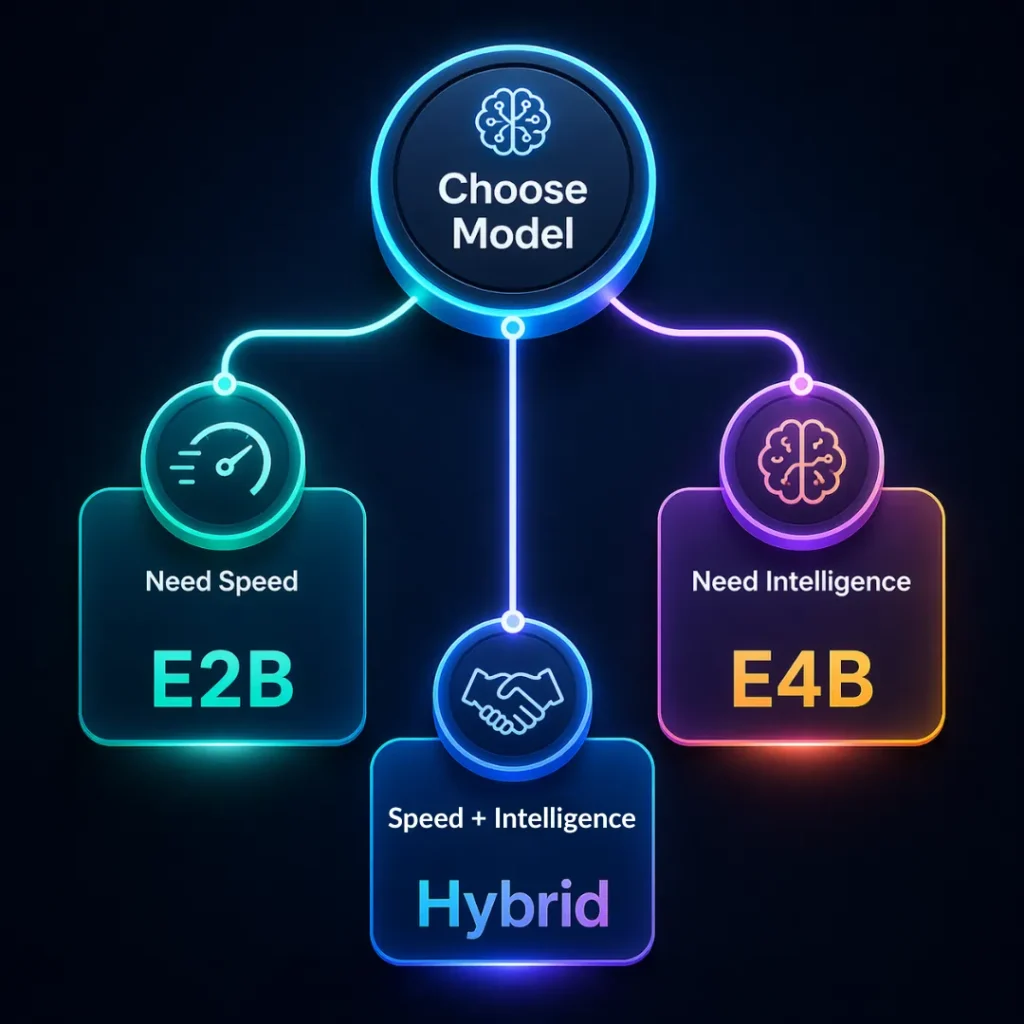
Choose E2B if your priority is speed, stability, and cost-efficient scaling on Raspberry Pi. Choose E4B if your use case requires higher reasoning accuracy and can tolerate slower response times. For most real-world deployments, a hybrid approach delivers the best balance.
After evaluating performance, benchmarks, and use cases, the final decision comes down to aligning model capability with business requirements. In offline AI on Raspberry Pi, the goal is not to use the most powerful model-it’s to use the most effective model for the task.
Step 1: What Is Your Primary Use Case?
Start by defining what your system needs to do:
- Real-time interaction or automation → prioritize speed → E2B
- Complex reasoning or analytics → prioritize quality → E4B
If your application spans both, a single-model approach will limit efficiency.
Step 2: What Are Your Performance Requirements?
Evaluate how critical responsiveness is
- Need instant or near real-time responses
→ E2B is the practical choice - Can tolerate delays for better output quality
- → E4B becomes viable
For most local LLM Raspberry Pi applications, latency directly affects usability, making speed a key factor.
Step 3: What Are Your Hardware Constraints?
Raspberry Pi 5 has limits that must be considered:
- Limited RAM and CPU resources
- No GPU acceleration
- Thermal constraints under load
If your setup is not heavily optimized:
- E2B will run reliably
- E4B may struggle without tuning
Step 4: What Is Your Cost and Scaling Strategy?
Your model choice directly impacts scalability:
- E2B enables cost-efficient scaling
- Lower energy usage
- More devices per budget
- Easier replication across locations
- E4B increases per-device cost
- Higher resource consumption
- More optimization effort is required
Step 5: Do You Need a Hybrid Model Strategy?
In most production environments, the best solution is not choosing one model—but combining both strategically.
Recommended approach:
- Use E2B for:
- Real-time processing
- Automation and system control
- High-frequency tasks
- Use E4B for:
- Complex queries
- Advanced reasoning
- High-value decision workflows
This ensures:
- Faster overall system performance
- Efficient resource utilization
- Improved output quality where it matters most
Decision Framework (Quick Summary)
- If your priority is speed, scalability, and efficiency → Choose E2B
- If your priority is accuracy, reasoning, and advanced AI capability → Choose E4B
- If you need both → Adopt a hybrid approach
Decision Framework (Quick Summary)
Strategic Perspective
For businesses deploying Gemma 4 Raspberry Pi solutions, the decision should be driven by ROI, not model size.
- Overengineering with E4B increases cost without proportional value
- Underutilizing E2B limits system potential
The optimal approach is precision in model selection, combined with continuous optimization.
Organizations implementing edge AI models at scale often rely on structured frameworks to make these decisions. With the right guidance-such as that provided by CrossShores, teams can align performance, cost, and scalability without unnecessary trial and error.
Final Takeaway
- There is no universal “best model”—only the best fit for your use case
- E2B is the default for efficient edge deployments
- E4B is a targeted upgrade for complex tasks
- A hybrid strategy delivers the strongest real-world results
13. What Are the Most Asked Questions About Gemma 4 on Raspberry Pi?
1. Which Gemma 4 model is best for Raspberry Pi?
Answer:
For most Gemma 4 Raspberry Pi deployments, E2B is the best choice because it delivers faster inference, lower memory usage, and stable performance. E4B is better for complex reasoning tasks but requires optimization and may introduce higher latency on resource-constrained devices.
2. Can Raspberry Pi 5 run Gemma 4 models offline?
Answer:
Yes, Raspberry Pi 5 can run Gemma 4 models offline, especially optimized versions like E2B. Performance depends on quantization, cooling, and the inference engine used. Running models locally ensures better privacy, lower latency, and eliminates dependency on cloud-based AI services.
3. How much RAM is required to run Gemma 4 on Raspberry Pi?
Answer:
Running Gemma 4 on Raspberry Pi typically requires 2–4 GB RAM for E2B and 5–8 GB for E4B with quantization. For stable performance, an 8GB Raspberry Pi 5 is recommended, especially when handling continuous workloads or running multiple processes.
4. What is the best way to run local LLMs on Raspberry Pi?
Answer:
The most efficient way to run a local LLM Raspberry Pi setup is using llama.cpp with quantized models, as it is optimized for CPU-based inference. Ollama is a good alternative for easier setup, while LiteRT is suitable for more structured, scalable deployments.
5. Is E4B too heavy for Raspberry Pi?
Answer:
E4B can be heavy for Raspberry Pi because it requires more memory and processing power. Without optimization, it may cause higher latency and thermal issues. However, with quantization and proper tuning, E4B can run for selective, high-value tasks.
6. What are the main use cases of offline AI on Raspberry Pi?
Answer:
Common offline AI on Raspberry Pi use cases include smart home automation, local AI assistants, IoT and IIoT monitoring, robotics control systems, and edge-based analytics. These applications benefit from low latency, improved privacy, and the ability to operate without internet connectivity.
7. Can I use both E2B and E4B together on Raspberry Pi?
Answer:
Yes, using both E2B and E4B together is a recommended approach. E2B handles real-time tasks efficiently, while E4B can be used for complex queries and reasoning. This hybrid strategy improves performance, balances resource usage, and enhances overall system capability.
8. Is Raspberry Pi powerful enough for edge AI models?
Answer:
Raspberry Pi 5 is powerful enough to run edge AI models, especially optimized ones like E2B. While it cannot match GPU-based systems, it performs well for lightweight and real-time applications when properly optimized, making it a practical choice for offline AI deployments.
14. What Is the Future of Edge AI Models on Raspberry Pi?
The future of edge AI models on Raspberry Pi is focused on smaller, faster, and more efficient models capable of running multimodal and agentic workflows entirely offline. As optimization improves, Raspberry Pi will support more advanced AI use cases with lower cost and higher scalability.
Edge AI is rapidly evolving from experimental setups to production-ready systems, and Raspberry Pi is becoming a key platform in this transition. With the rise of offline AI on Raspberry Pi, the focus is shifting toward efficiency, autonomy, and real-world deployment at scale.
How Are Edge AI Models Evolving?
The next generation of edge AI models is being designed specifically for constrained hardware environments:
- Smaller Model Architectures
More efficient models that deliver high-quality outputs with fewer parameters - Better Quantization Techniques
Advanced compression methods enabling faster inference with minimal accuracy loss - Improved CPU Optimization
Enhanced performance without relying on GPUs or external accelerators - On-Device Learning Capabilities
Emerging techniques allowing limited local adaptation without cloud dependency
What Role Will Raspberry Pi Play in This Future?
Raspberry Pi is uniquely positioned as a low-cost, scalable edge AI platform:
- Enables mass deployment of AI-powered devices
- Supports localized processing for privacy-sensitive applications
- Reduces dependency on cloud infrastructure
- Acts as a foundation for distributed AI systems
As hardware continues to improve, Raspberry Pi will handle increasingly complex workloads, making local LLM Raspberry Pi setups more powerful and practical.
What New Use Cases Will Emerge?
As capabilities expand, new applications of offline AI on Raspberry Pi will become mainstream:
- Multimodal AI systems
Combining text, vision, and audio processing locally - Autonomous smart environments
Homes, factories, and offices running AI without cloud reliance - Advanced robotics
Real-time decision-making and interaction at the edge - Industrial edge intelligence (IIoT)
Predictive maintenance and real-time analytics on-site - Personal AI assistants
Fully private, always-available assistants running locally
How Will This Impact Businesses?
The evolution of edge AI models will redefine how organizations build and deploy AI systems:
- Lower operational costs
Reduced reliance on cloud infrastructure and APIs - Faster decision-making
Real-time processing without network delays - Enhanced data privacy and compliance
Sensitive data remains on-device - Scalable deployment models
Easy replication across multiple devices and locations
Strategic Outlook
The shift toward Gemma 4 Raspberry Pi-style deployments signals a broader transformation:
AI is moving from centralized systems to distributed, edge-first architectures.
Businesses that adopt early will gain:
- Competitive advantage in cost efficiency
- Greater control over data and infrastructure
- Faster innovation cycles
Organizations already implementing these systems—often with structured deployment strategies supported by partners like CrossShores—are positioning themselves ahead in this transition by building scalable, offline-first AI solutions.
Final Takeaway
- Edge AI is becoming smaller, faster, and more autonomous
- Raspberry Pi will play a central role in scalable offline AI deployments
- The future belongs to systems that are efficient, private, and locally intelligent
FAQs
1. What is the difference between Gemma 4 E2B and E4B on Raspberry Pi?
In Gemma 4 Raspberry Pi setups, E2B is optimized for speed and efficiency, making it suitable for real-time applications on Raspberry Pi. E4B offers better reasoning and output quality but requires more RAM and processing power. The choice depends on whether performance or accuracy is your priority.
2. Which Gemma 4 model is best for Raspberry Pi deployment?
For most Gemma 4 Raspberry Pi deployments, E2B is the better choice due to its lower memory usage and faster inference speed. E4B is recommended only if your application requires deeper reasoning and your hardware setup can handle higher resource consumption.
3. Can Raspberry Pi run Gemma 4 models offline?
Yes, Raspberry Pi can run Gemma 4 models offline using optimized inference engines like llama.cpp. Offline deployment ensures data privacy, reduced latency, and independence from cloud infrastructure.
4. How much RAM is required to run Gemma 4 on Raspberry Pi?
E2B can typically run on 4GB–8GB RAM setups with optimization, while E4B generally requires 8GB or more for stable performance. Using quantized models can significantly reduce memory requirements.
5. Is Gemma 4 suitable for edge AI applications?
Yes, Gemma 4 models are designed for efficient inference and can be adapted for edge AI use cases such as automation, IoT intelligence, and local data processing. They are especially useful when low latency and offline capability are critical.
6. What are the limitations of running LLMs on Raspberry Pi?
The main limitations include restricted RAM, lower CPU performance, and lack of GPU acceleration. These constraints can affect model size, inference speed, and response quality, especially for larger models like E4B.
7. How can I improve performance of Gemma 4 on Raspberry Pi?
You can improve performance by using quantized models, efficient inference frameworks, and optimized libraries. Reducing model size and limiting context length also helps achieve faster responses on edge devices.
8. Is E4B worth using on Raspberry Pi?
E4B is worth using only when your application demands higher-quality reasoning or complex outputs. However, for most real-time or resource-constrained scenarios, the performance trade-offs make E2B the more practical option.
9. What are common use cases for Gemma 4 on Raspberry Pi?
Common use cases include smart assistants, local chatbots, automation systems, IoT analytics, and offline AI processing. These applications benefit from low latency and on-device computation.
10. Which tools are used to run Gemma models on Raspberry Pi?
Popular tools include llama.cpp and lightweight deployment frameworks that support quantized models. These tools enable efficient execution of LLMs on limited hardware like Raspberry Pi.